かつてのIntel(及び互換)CPU命令セットx86(32bit)と、それを64bitに拡張した現在一般的にPCで使われている命令セットx86-64で、同じC・C++ソースコードからそれぞれ最適化設定を有効にしてコンパイルをかけてもネイティブなlong long(64bit)型の演算、標準で定義されているSIMDの有効化、増加したレジスタ分に関連した最適化のみ行われると思っていたし、ググったりCopliotに聞いてもそのような回答が出てくるのだけど、実際に確認してみたら(コンパイラにもよるだろうが)インライン・ループ展開も積極的に行うようだった。
まあ今更、新規にPC向けのプログラムでx86にして組むことはかなり稀とも思うんで完全に無駄知識だとは思う。
でも今時のコンパイラはこういう最適化は普通にやっているので、古いTipsを参考にして、わざわざ人間がループ展開したり独自転送関数を作る必要性はないというという参考にはなるかも。
まずはテストに使うCコードはこれ

RGBAのビットマップに16*16サイズのアイコン画像をそのまま貼り付けるようなものだ。X一列分16ドット(*RGBAなので4)は(std::)memcpy関数で一気に貼り付け、それをfor文で16回ループするというもの。
これをx64、最適化オプション/O2でMSVCを使いコンパイルすると以下のようなアセンブラで出力される。(長すぎるのでアセンブラの最初と最後だけ)


アセンブラがわからない人に説明すると、転送が16バイト(128bit)の倍数ということでmovupsという128bit単位でメモリ転送を行うSSE命令を使ってメモリ→レジスタ・レジスタ→メモリで2命令を64回、計128命令並べて完全にループ展開されている。for文が消えてmemcpy・ポインタ更新を16回並べたコードと同一になっている。
そして上記の同じソースコード・同じコンパイラ・同じ最適化オプションでターゲットのみをx86に切り替えて出力されるアセンブラがこちら

こちらのコードではかなり短くなって一画像に収まる長さだが、memcpy・ポインタ更新の部分がmovupsを2*4命令使って(16バイト*4命令)いるものの、素直に16回ループ(レジスタedxの値をsub命令で1づつ減少させて0になっていなければjne命令で先頭に戻る)させている。SIMD命令を使ったり条件判定をソースコードから逆にしているとはいえ率直にソースコードをアセンブラ化したというようなもの。
何故にこのような差異が発生するのか推測になるが、x86-64のほうが扱えるCPUの世代が新しく大容量のキャッシュメモリを備えていたりプリフェッチも増強されているCPUの可能性が高いので、命令数が増えてプログラムサイズが増大したとしても積極的に展開したほうが高速になりやすい傾向があると判断されているのか、また今更x86を指定してコンパイルする環境ではその逆になっていると判断されているのか、x86向けのコンパイラへの保守が使用頻度の問題でおろそかになっているといったところなのかもしれない。
ちなみに、元のソースコードでmemcpyではなくfor文と配列参照で代入する形にしてx64・/O2でコンパイルすると

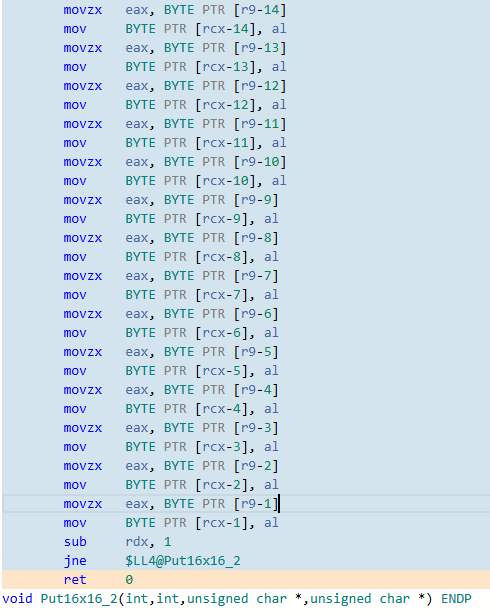
64バイト分展開されているとはいえSIMD命令は使われず単純にmov命令で1バイトづつ転送、しかも結局16回ループ処理が発生するという中途半端な最適化になっている。128回転送命令を並べるとして流石にそれ以上は長すぎるのだろう。
他のサイトでも記載されている話ではあるが、標準関数のmemcpyは転送バイト数が16バイト単位であれば率直にSIMD命令に置き替えられる可能性が高くなるので、代用memcpyを自作するとか、char型をint(long long)型にして転送するとかややこしいことはせず、アライメントや転送バイト数だけ意識していったほうがいい。