先に概要を書くと
- caseの値は連番かつ昇順(上から小さい数で下に行くほど増えていく)となるように心がける。ある程度caseが多ければあとは勝手にコンパイラがテーブルジャンプ最適化を行う。
- goto文やreturn文などでswitch文途中から抜けないようにする。あるとテーブルジャンプ最適化が行われない。
- MSVC(Visual Studio)でコンパイルする場合、default:の箇所に__assume(0);と記述すれば上記二つを無視して強制的にテーブルジャンプ最適化が行われる。ただし、goto・return等でのswitch抜けがあるまま実行すると例外エラーが発生する。
- 追記:上記の__assume(0)はC++23から「std::unreachable()」で標準化
FM TOWNSエミュレータ「津軽」を弄っていて、どうもエミュレーターの実行速度が既にあるTOWNSエミュレータの「うんづ」や同じようなx86 CPUを積んだPC(PC98・IBM PC)のエミュレータと比べても遅過ぎるのが謎だったのでちゃんと調べることにしたのが事の始まり。どのくらい遅いのかというと現在Core i5 12600を搭載したPCを使っているのだけど、486 66MHzくらいのCPU速度をエミュレートするのがギリギリといったところ。エミュレータには対象のマシンよりも何倍もの性能を持ったものが必要なのは仕方ないにしても、シングルコアで比較してもおそらく300倍差があるんだからもっと早くても良さそうだ。簡単に考えるとエミュレートするCPUの1命令を実行するために、ホスト側のCPUでは300命令も実行して再現しようとしているからここまで遅いんですね。
公開されている津軽のソースコードを見ても他のエミュレータと比べても大差ないようなCPUコアの実装でコードを見ただけでは全く原因がわからず、Visual Studioの診断ツールを実行(RelWithDebInfo設定でコンパイルし、「デバックの開始」ボタンを押してCPU時間の測定で記録)し、コードで時間がかかっている処理の場所を可視化したところ
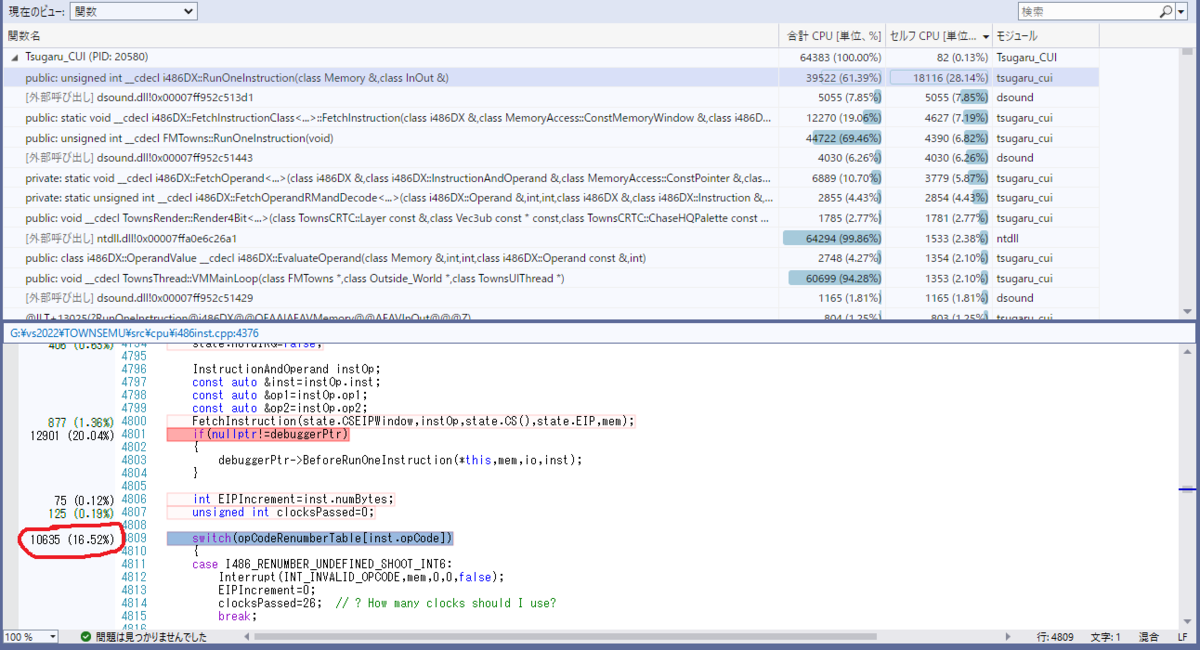
CPUの一命令を実行するRunOneInstruction関数で、CPU命令を読み込むFetchInstruction関数内の処理を除くと、読み込まれたCPU命令を元に分岐して処理を実行するswitch文の一か所だけで、なんとプログラム全体の約16%もの処理時間がかかっている。
このswitch文を確認すると
switch
{
case 0:
≀
break;
case 1:
≀
break;
case 2:
≀
break;
case 3:
≀
break;
≀
case 33:
≀
break;
case 39:
≀
break;
≀
case 34:
≀
break;
≀
case 22:
≀
break;
とCPU命令のオペコード数値順じゃなく、命令のオペランド(実行する命令の演算値の場所を指定するところ)順に並べているのか微妙に飛び飛びにcaseの値が指定されている。これだとジャンプテーブルという配列にジャンプ先のアドレスを入れてそこから読み込んですぐ分岐が行われるテーブルジャンプという実装方法での最適化がコンパイラで行われず、大量のif~else if~文に置き換えられてしまうのだろう。命令数を数えたところなんと308個。それが全部if文となり分岐するかどうか調べられるので、処理に時間がかかっていたのだ。
本来ならば、
case 0:
case1:
≀
case 27:
≀
case 34:
≀
case 39:
≀
とちゃんと整理すればいいのだろうが、可視化しやすいようにこの並び順にしていた可能性があるのと、そもそも308個のcase文を並び変えるのが面倒だし、並び替えに失敗していたら最適化が行われないとなるので何とかこのままの状態でテーブルジャンプ最適化が行われないかと調べたら、同じようにエミュレータのCPUコア実装でテーブルジャンプの考察を記載しているサイトにてMSVCのみではあるが、default:に__assume(0)と追記するとテーブルジャンプに展開されるとあったので藁にも縋る思いで、
default:
#if defined(_MSC_VER)
__assume(0);
#endif
とこの3行(実質1行)のみ追記して他は手つかずのまま再度診断ツールを実行したところ、
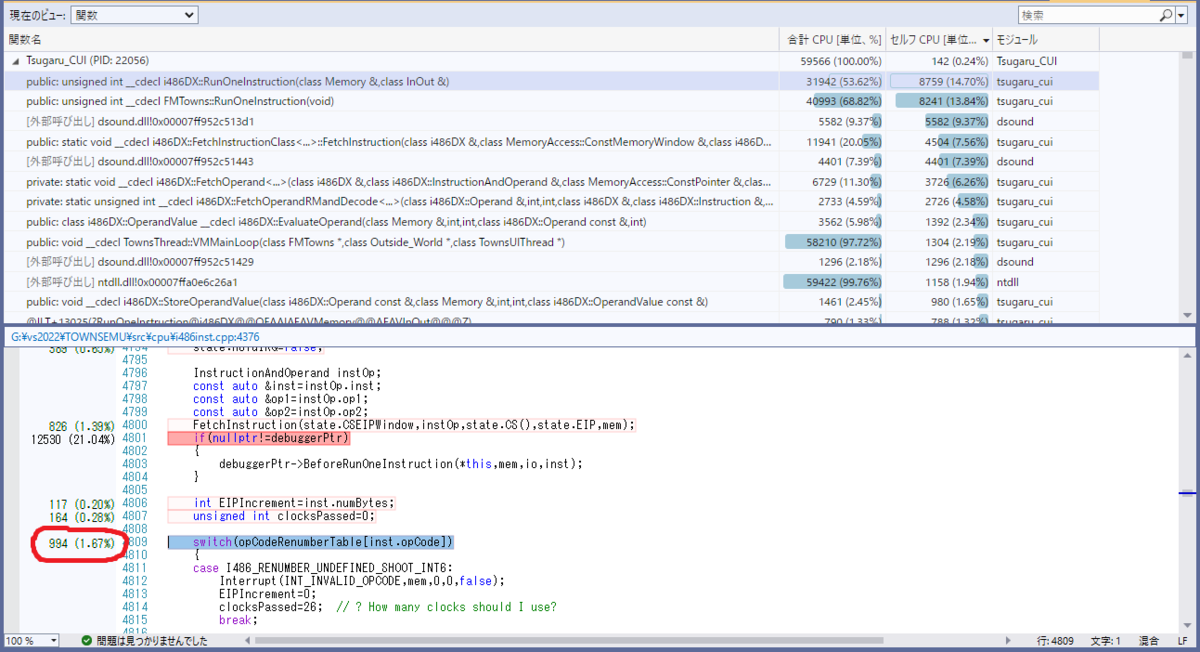
なんということでしょう(ビフォーアフター風)
約16%もCPU時間を占めていたswitch文が約1.6%とほぼ十分の一まで負荷が下がってくれました。

津軽のエミュレート速度を図る方法、コマンド入力で「pri timebalance」で1ms毎のエミュレートの進行速度を示す値値平均でも、改良前はCore i5 12600環境でVM CPU速度 66MHz設定におけるTownsOS上の計測値は約170000だったのが、

テーブルジャンプ実装後は約220000まで向上。たった1行だけで1.3倍の高速化が実現できた。もう一か所テーブルジャンプ化されていないそこそこ長いswitch文があってこちらもテーブルジャンプ化(__assume(0)追記だけでなくcaseも整理)したが、こちらはRunOneInstruction内ほどの効果はなかった。このswitch文以外にもまだボトルネックになっているところはあるが、これだけでもだいぶ動作が軽くなった。絶大な効果があったのでGithubでpull requestを送信し、さっそくmerge(コードの変更を承認)される。まだGithub上のコードでのみ反映されていないが、次回のリリース版では前バージョンよりも軽くなっているはずだ。
なお、VCでは__assume(0);でまず間違いなくテーブルジャンプ化されるのだが、case内でgotoやreturnなどを使いswitch文途中で抜けるような処理を書きそこに到達すると例外エラーが発生してしまうので要注意。caseで処理が終わる場合はbreak;でswitch文下に続くようにする。